

About
Chronosphere is a purpose-built observability platform engineered for organizations running Kubernetes and microservices at scale. Recognized as a Leader in the 2025 Gartner® Magic Quadrant™ for Observability Platforms, Chronosphere delivers industry-leading 99.99% reliability even at tens of millions of data points per second. The platform unifies metrics, logs, distributed traces, and events (MELT) in a single pane of glass, enabling faster root cause analysis and incident resolution. Its Control Plane empowers teams to analyze, refine, and route telemetry data—aligning data costs with business value and eliminating waste from unused data. Key capabilities include Chronosphere Lens for integrated, contextual incident response workflows; Differential Diagnosis (DDx) for queryless, guided troubleshooting using metrics or traces (no expertise required); and Chronosphere SLOs for managing service-level objectives in dynamic containerized environments. The Telemetry Pipeline—powered by Fluent Bit—enables turnkey log collection, aggregation, transformation, and forwarding from any source to any destination via a low-code/no-code interface. Chronosphere also supports AI Workload Observability, helping teams scale AI operations without growing costs, alongside application, business, and infrastructure observability layers. It ingests data via Prometheus, OpenTelemetry, and other open-source standards, making it flexible for modern DevOps stacks. Ideal for platform engineering teams, SREs, and DevOps organizations at mid-to-large enterprises.
Key Features
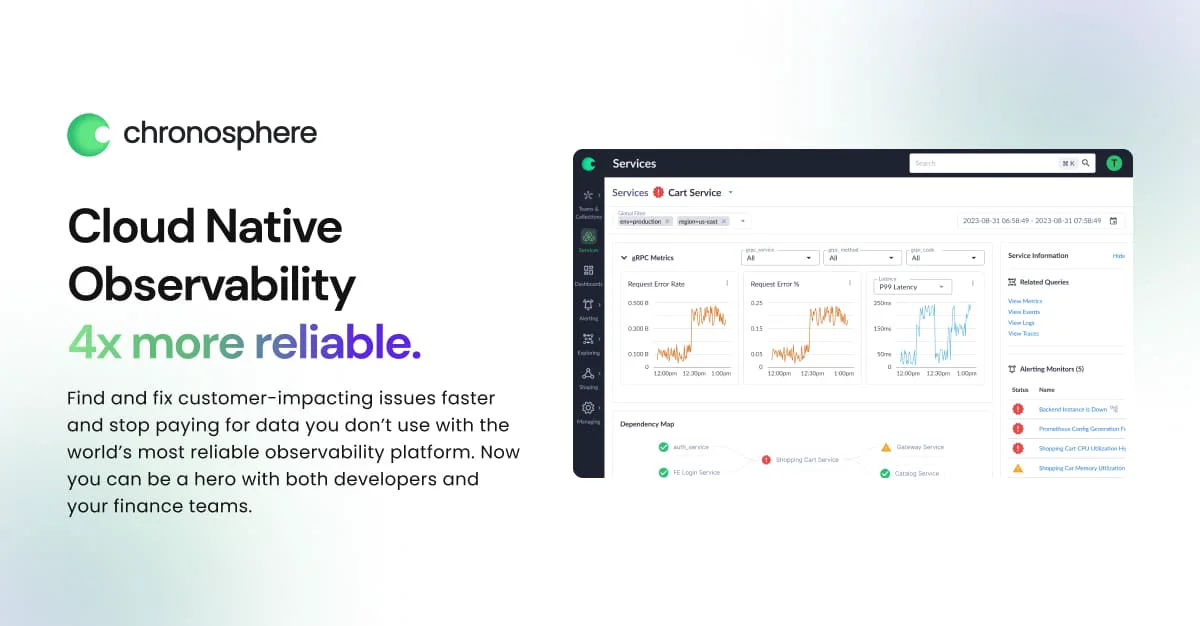
- Unified MELT Observability: Consolidates metrics, events, logs, and distributed traces into a single platform for full-stack visibility across containerized environments.
- Chronosphere Lens – Incident Response: Resolve incidents faster with integrated, contextual data surfaced throughout the entire incident response workflow.
- Differential Diagnosis (DDx): Queryless, guided troubleshooting using metrics or traces that requires no specialized expertise, dramatically reducing time-to-resolution.
- Telemetry Pipeline with Fluent Bit: Collect, aggregate, transform, and route logs and security events from any source to any destination using a low-code/no-code interface.
- Data Cost Control: Control Rules and the Control Plane help teams reduce observability spend by aligning data ingestion costs with actual business value.
Use Cases
- Platform engineering and SRE teams at enterprises managing large-scale Kubernetes clusters who need unified visibility across metrics, logs, and traces.
- DevOps organizations struggling with runaway observability costs from high-cardinality metrics or excessive log volumes, seeking intelligent data reduction.
- Companies running distributed microservices architectures that need fast, guided root cause analysis during production incidents without requiring deep query expertise.
- Security operations teams needing to collect, pre-process, and route security logs from diverse sources to any SIEM destination.
- Organizations scaling AI/ML infrastructure who need to monitor model serving performance and resource utilization without dramatically increasing observability spend.
Pros
- Enterprise Reliability: Proven 99.99% uptime even at tens of millions of data points per second, making it trusted for mission-critical production environments.
- Kubernetes-Native Design: Purpose-built for containerized, microservices architectures—not retrofitted from legacy monitoring tools—ensuring optimal performance at scale.
- Open Standards Support: Ingests data via Prometheus, OpenTelemetry, and other open-source formats, allowing seamless integration with existing DevOps toolchains.
- Gartner Magic Quadrant Leader: Recognized as a Leader for the second consecutive year in the 2025 Gartner® Magic Quadrant™ for Observability Platforms.
Cons
- Enterprise Pricing: Designed for mid-to-large enterprises; pricing and scale may be prohibitive for smaller teams or startups with limited observability budgets.
- Demo-Required Onboarding: No self-serve trial is apparent from the website; prospective customers must request a demo, adding friction to initial evaluation.
- Learning Curve for Advanced Features: While DDx aims to simplify troubleshooting, fully leveraging SLO management, Control Plane tuning, and telemetry pipelines may require dedicated expertise.
Frequently Asked Questions
What makes Chronosphere different from general-purpose monitoring tools like Datadog or Prometheus?
Chronosphere is purpose-built for Kubernetes and microservices environments, offering superior scalability, cost control mechanisms, and a unified MELT data platform. Unlike general-purpose tools, it provides built-in controls to match data costs with value and a guided troubleshooting experience (DDx) that doesn't require query expertise.
How does Chronosphere help control observability costs?
Chronosphere's Control Plane and Control Rules allow teams to analyze incoming telemetry, remove low-value data before storage, and route data intelligently—so you only pay for what matters. This prevents the runaway costs common with high-cardinality metric and log data.
What is Differential Diagnosis (DDx)?
DDx is Chronosphere's queryless, guided troubleshooting feature. It automatically surfaces likely root causes using metrics or traces without requiring engineers to write complex queries, making incident investigation faster and accessible to a broader range of team members.
Does Chronosphere support OpenTelemetry and Prometheus?
Yes. Chronosphere natively ingests metrics and traces via Prometheus, OpenTelemetry, and other open-source formats, making it easy to integrate into modern cloud-native stacks without vendor lock-in at the data collection layer.
Can Chronosphere be used for AI workload observability?
Yes. Chronosphere offers AI Workload Observability capabilities specifically designed to help teams monitor and scale AI operations—such as model inference infrastructure—without proportionally growing observability costs.







