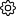

About
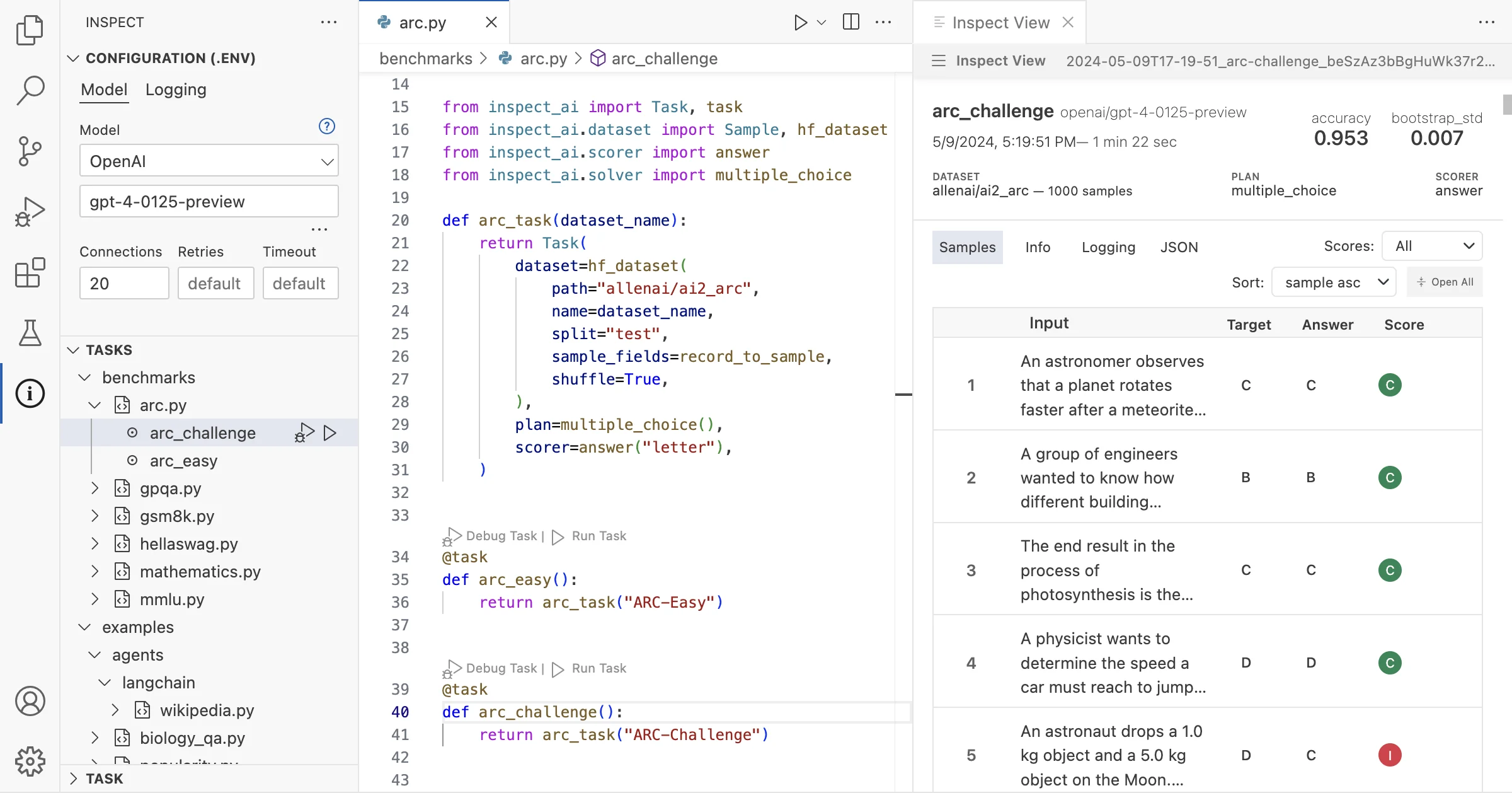
Inspect is an open-source LLM evaluation framework created by the UK AI Security Institute, designed to help researchers and developers rigorously benchmark AI models across coding, reasoning, agentic tasks, knowledge, behavior, and multi-modal understanding. The framework provides clean, reusable interfaces for building and running evaluations, along with a library of over 100 pre-built benchmarks ready to execute against any supported model. Inspect integrates with virtually all major model providers—OpenAI, Anthropic, Google, Grok, Mistral, Hugging Face, AWS Bedrock, Azure AI, TogetherAI, Groq, Cloudflare, and local model runtimes like vLLM and Ollama. Key capabilities include flexible tool-calling support (custom tools, MCP tools, and built-in bash, Python, web search, web browsing, and computer interaction tools), comprehensive agent evaluation features (ReAct agents, multi-agent primitives, and support for external agents such as Claude Code, Codex CLI, and Gemini CLI), and a robust sandboxing system for safely running model-generated code in Docker, Kubernetes, Modal, Proxmox, and more. Inspect ships with a web-based Inspect View for monitoring and visualizing evaluation results, and a VS Code Extension for authoring and debugging. Installable via pip, it targets AI safety researchers, ML engineers, and organizations that need rigorous, reproducible model evaluations.
Key Features
- 100+ Pre-Built Evaluations: Comes with a library of over 100 ready-to-run benchmark evaluations covering coding, reasoning, knowledge, behavior, and multi-modal tasks.
- Flexible Tool Calling: Supports custom tools, MCP tools, and built-in tools including bash, Python, web search, web browsing, and computer interaction for rich evaluation scenarios.
- Agent Evaluation Support: Enables evaluation of agentic AI systems with built-in ReAct agents, multi-agent primitives, and support for external agents like Claude Code, Codex CLI, and Gemini CLI.
- Secure Sandboxing: Safely executes untrusted model-generated code in Docker, Kubernetes, Modal, Proxmox, and other environments via an extensible sandboxing API.
- Broad Model Provider Support: Works with OpenAI, Anthropic, Google, Grok, Mistral, Hugging Face, AWS Bedrock, Azure AI, vLLM, Ollama, and many more providers out of the box.
Use Cases
- AI safety researchers running standardized benchmarks to measure LLM capabilities and risks across reasoning, coding, and behavioral tasks.
- ML engineers evaluating and comparing model performance before deployment across multiple providers and configurations.
- Organizations conducting structured agentic evaluations to assess AI systems on complex multi-step and tool-use tasks.
- Developers building custom LLM evaluation pipelines using Inspect's extensible dataset, solver, and scorer components.
- Research teams monitoring model capability changes across versions using the web-based Inspect View visualization tool.
Pros
- Fully Open Source: Free to use and community-auditable, developed by the UK AI Security Institute—making it a trusted choice for AI safety and research communities.
- Extensive Model Compatibility: Supports virtually all major LLM providers as well as local models, making it versatile for diverse evaluation workflows without vendor lock-in.
- Rich Built-In Tooling: Ships with a VS Code extension and a web-based Inspect View for monitoring, debugging, and visualizing evaluation runs with minimal setup.
- Highly Extensible: Clean interfaces and an extension API allow teams to build custom datasets, solvers, scorers, tools, and sandboxes tailored to their needs.
Cons
- Python and CLI Required: The framework is Python-centric and command-line driven, which may be a barrier for non-technical users or teams without a Python workflow.
- Separate API Key Management: Using proprietary models requires obtaining and managing API keys from each provider individually, adding administrative overhead.
- Learning Curve for Custom Evals: Building custom evaluations requires understanding Inspect's core components—datasets, solvers, and scorers—which takes time to learn effectively.
Frequently Asked Questions
What is Inspect AI?
Inspect is an open-source framework for LLM evaluations developed by the UK AI Security Institute. It enables researchers and developers to benchmark AI models across coding, reasoning, agentic tasks, knowledge, behavior, and multi-modal understanding.
Which model providers does Inspect support?
Inspect supports OpenAI, Anthropic, Google, Grok, Mistral, Hugging Face, AWS Bedrock, Azure AI, TogetherAI, Groq, Cloudflare, Goodfire, and local models via vLLM, Ollama, llama-cpp-python, TransformerLens, and nnterp.
Is Inspect AI free to use?
Yes, Inspect is fully open source and free. Install it with `pip install inspect-ai`. Note that using proprietary model APIs (e.g., OpenAI, Anthropic) may incur usage costs from those providers.
Can Inspect evaluate agentic AI systems?
Yes. Inspect supports ReAct agents, multi-agent primitives, and external agents such as Claude Code, Codex CLI, and Gemini CLI, making it well-suited for complex agentic task evaluations.
How do I get started with Inspect?
Run `pip install inspect-ai` to install, optionally install the VS Code extension, configure your model provider API key, write an evaluation script, and execute it with the `inspect eval` CLI command.








