

About
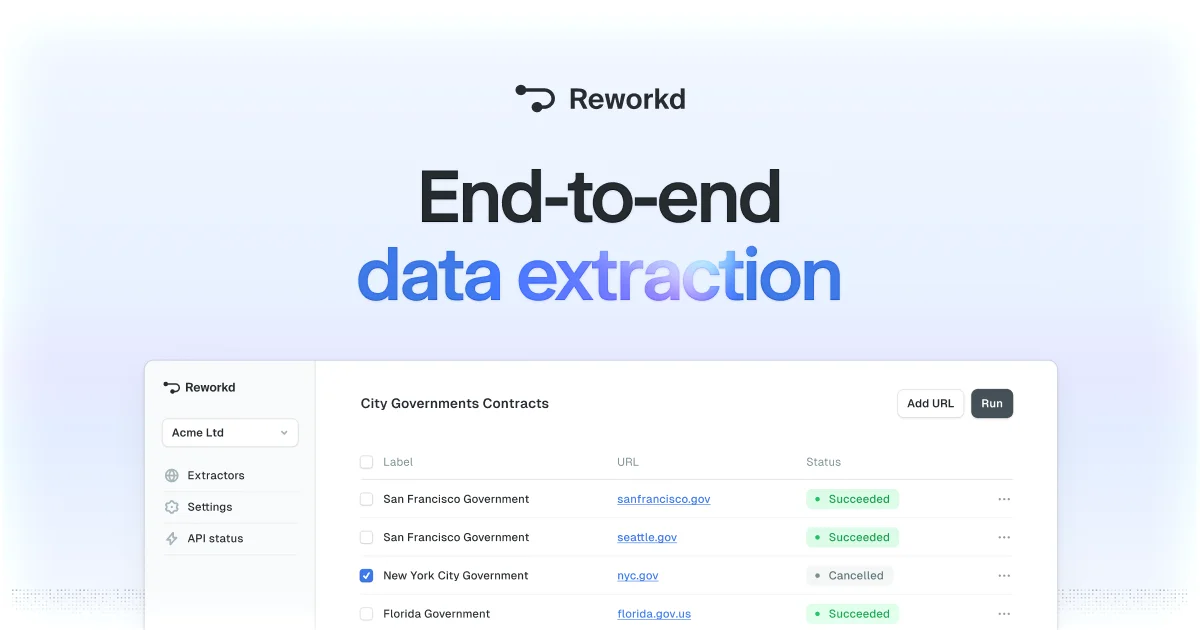
Reworkd was an end-to-end web data extraction platform built to eliminate the complexity of large-scale web scraping. Rather than requiring engineers to write and maintain custom scraping scripts, Reworkd automated the full pipeline — scanning target websites, generating extraction code, running crawlers, validating results, and delivering structured data output — all from a single, no-code interface. The platform addressed some of the hardest problems in web data collection: handling pagination and infinite scroll, managing dynamic JavaScript-rendered content, dealing with rate limiting, rotating proxies, and automatically retrying on failures. Teams could monitor hundreds or thousands of sites simultaneously without building custom infrastructure. Reworkd was particularly well-suited for enterprises, research teams, and data-driven startups that needed continuous streams of web data — such as government regulations, competitor intelligence, market research, or product catalogs — without dedicating engineering resources to scraper maintenance. The company was backed by prominent investors including Paul Graham (Y Combinator), Nat Friedman (ex-CEO of GitHub), and Daniel Gross (co-founder of SSI), reflecting strong industry confidence in its approach to no-code data infrastructure. Note: Reworkd announced the sunset of its product on February 6, 2025.
Key Features
- Fully Automated Data Pipeline: Reworkd scans websites, generates extraction code, runs crawlers, validates results, and outputs structured data — entirely end-to-end with no manual steps.
- No-Code Interface: Non-technical users can set up and manage large-scale web scraping workflows without writing a single line of code.
- Dynamic Content & Pagination Handling: Automatically manages complex web scenarios including infinite scroll, JavaScript-rendered pages, and multi-page pagination.
- Scalable Multi-Site Crawling: Designed to handle hundreds or thousands of websites simultaneously, with built-in rate limiting, proxy rotation, and automatic retries on failures.
- Automatic Maintenance & Monitoring: Detects when target websites change their structure and adapts extraction logic automatically, reducing ongoing maintenance burden.
Use Cases
- Extracting and monitoring government regulations and public procurement data across hundreds of official sources
- Aggregating competitor pricing, product listings, and inventory data from e-commerce websites at scale
- Building automated market research pipelines by collecting structured data from news sites, directories, and industry portals
- Scraping startup and company directories (like YC) to enrich CRM or lead generation databases without manual effort
- Collecting and structuring public sector and compliance data for regulatory intelligence and reporting workflows
Pros
- Zero Engineering Overhead: Eliminates the need for dedicated engineers to write, monitor, and maintain custom scraping scripts, saving significant time and cost.
- Handles Real-World Complexity: Built-in solutions for the hardest scraping challenges — dynamic content, rate limiting, proxy management, and retries — work out of the box.
- Enterprise-Grade Backing: Backed by Y Combinator, Nat Friedman, and Daniel Gross, indicating strong product credibility and investor confidence.
Cons
- Product Sunset: Reworkd announced it was sunsetting its product on February 6, 2025, making it unavailable for new or existing users.
- Enterprise-Focused Pricing: Pricing required booking an intro call, suggesting it was not self-serve and may have been cost-prohibitive for smaller teams.
- Narrow Use Case Scope: Focused exclusively on web data extraction, so teams needing broader data transformation or analytics capabilities would require additional tools.
Frequently Asked Questions
What is Reworkd?
Reworkd was an AI-powered, no-code web scraping platform that automated end-to-end web data extraction pipelines, handling everything from crawling and parsing to validation and structured data output.
Does Reworkd require coding skills?
No. Reworkd was built for teams without dedicated engineering resources. Its no-code interface allowed users to set up and manage complex data extraction workflows without writing any code.
How did Reworkd handle complex websites?
Reworkd automatically handled pagination, infinite scroll, JavaScript-rendered dynamic content, rate limiting, proxy rotation, and failure retries — all without manual configuration.
Who was Reworkd designed for?
Reworkd targeted enterprises, data teams, startups, and research organizations that needed continuous, scalable web data collection without the cost of maintaining custom scraping infrastructure.
Is Reworkd still available?
No. Reworkd announced the sunset of its product on February 6, 2025. Users needing migration support were directed to contact the team at [email protected].







