
P
About
Evidently AI is an end-to-end AI evaluation and observability platform designed for teams building production-grade AI systems. It helps engineers and data scientists ensure their LLMs, RAG pipelines, and multi-agent workflows are safe, reliable, and performant before and after deployment. The platform is powered by the Evidently open-source Python library—one of the most trusted tools in the MLOps ecosystem with over 7,000 GitHub stars and 35 million downloads. It provides 100+ pre-built metrics covering hallucination detection, factuality, retrieval quality, PII detection, toxicity, sentiment, and adherence to guidelines. Teams can also create fully custom evaluations using LLM-as-a-judge, rule-based classifiers, or any custom metric logic. Key capabilities include synthetic and adversarial test data generation for edge cases, automated evaluation pipelines that produce shareable reports, and a live dashboard for continuous tracking of model quality across every update. The platform supports traditional ML models, classifiers, recommenders, and summarizers in addition to generative AI systems. Evidently AI is trusted by thousands of companies ranging from startups to enterprise teams, making it a production-ready solution for anyone serious about AI quality assurance and LLM observability.
Key Features
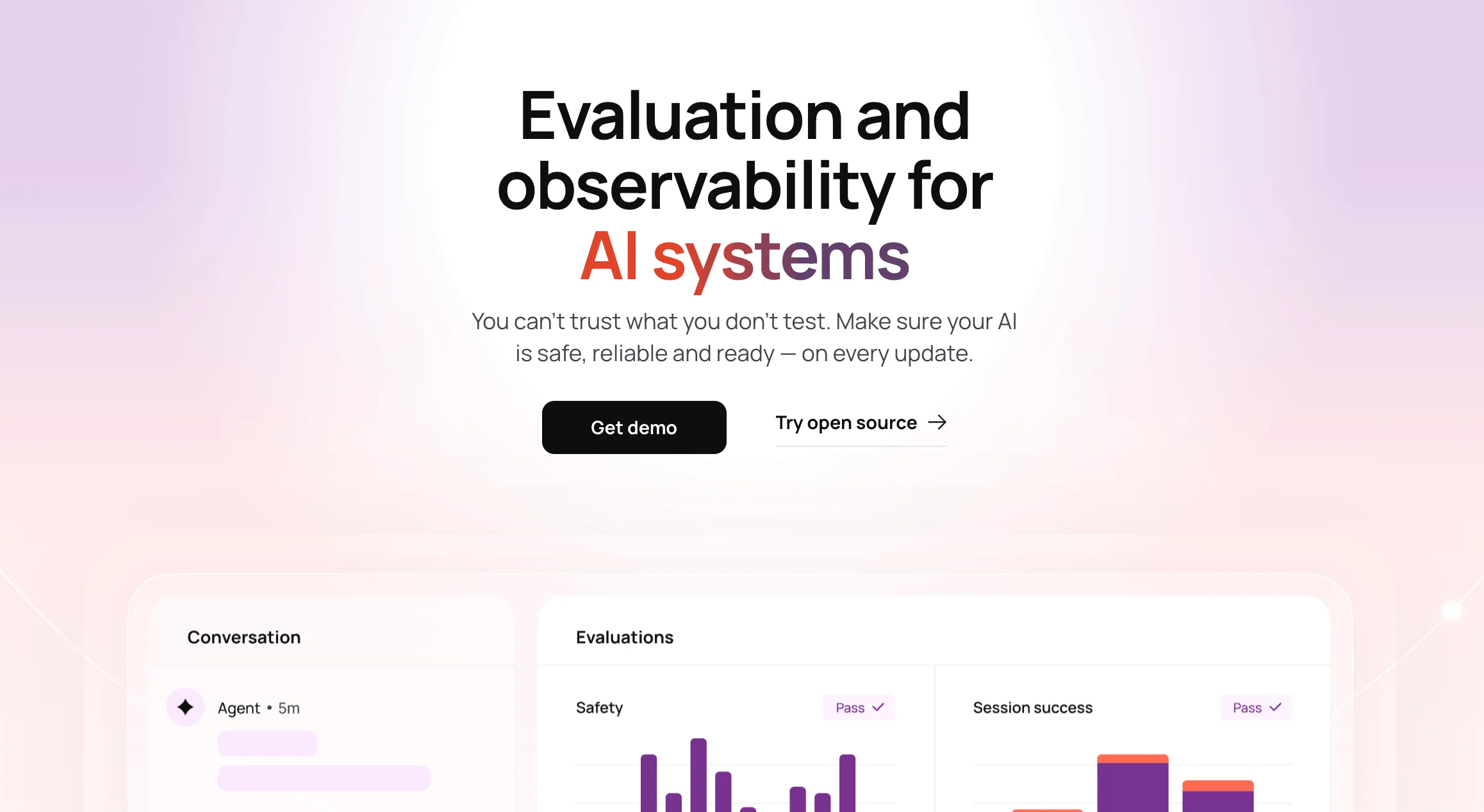
- LLM Evaluation with 100+ Metrics: Measure output accuracy, safety, hallucinations, PII leakage, toxicity, and more using a library of pre-built metrics or fully custom LLM-as-a-judge evaluations.
- Synthetic & Adversarial Test Data Generation: Automatically generate realistic, edge-case, and adversarial test inputs tailored to your use case—from harmless prompts to hostile jailbreak attempts.
- RAG Pipeline Testing: Evaluate retrieval quality, context relevance, and answer grounding to prevent hallucinations and improve accuracy in RAG chatbots and search systems.
- Continuous AI Monitoring Dashboard: Track model quality across every update with a live dashboard that detects drift, regressions, and emerging risks before they impact end users.
- AI Agent Workflow Validation: Go beyond single-turn responses to validate multi-step reasoning, tool use, and the full chain of actions in complex agentic workflows.
Use Cases
- Testing an LLM-powered chatbot for hallucinations, PII leaks, and policy violations before production release
- Evaluating retrieval quality and context relevance in a RAG-based knowledge assistant or enterprise chatbot
- Running adversarial red-teaming tests to identify jailbreak vulnerabilities in customer-facing AI products
- Monitoring production ML models for data drift and performance degradation across software updates
- Validating the end-to-end reasoning and tool-use quality of an autonomous AI agent workflow
Pros
- Open-Source Foundation: Built on a trusted open-source Python library with 7,000+ GitHub stars, making it transparent, extensible, and easy to integrate into existing MLOps pipelines.
- Comprehensive Metric Library: Over 100 built-in metrics covering hallucination, factuality, safety, PII, and custom business logic, with full support for custom LLM-as-a-judge evaluations.
- End-to-End Quality Coverage: Supports the full AI quality lifecycle—from offline testing and synthetic data generation to live production monitoring—in a single unified platform.
- Broad AI Paradigm Support: Handles LLMs, RAG systems, AI agents, classifiers, recommenders, and traditional ML models, making it a unified quality platform for diverse AI stacks.
Cons
- Technical Setup Required: Getting the most value requires engineering expertise in Python and familiarity with LLM evaluation concepts, which may create a barrier for non-technical teams.
- Paid Tier for Advanced Platform Features: While the open-source library is free, the full cloud platform with dashboards, continuous monitoring, and team collaboration requires a paid subscription.
- Developer-Centric Workflow: The tooling is primarily designed for ML engineers and data scientists; product managers or QA analysts without coding skills may find the experience challenging.
Frequently Asked Questions
Is Evidently AI open source?
Yes, the core Evidently Python library is fully open source and available on GitHub with 7,000+ stars and 35 million downloads. The cloud platform that adds dashboards, continuous monitoring, and team collaboration is a separate commercial product with a freemium model.
What types of AI systems can Evidently evaluate?
Evidently supports LLMs, RAG pipelines, AI agents and multi-step workflows, classifiers, recommenders, summarizers, and traditional ML models—covering the full range of modern AI system architectures.
How does Evidently detect hallucinations?
Evidently uses a combination of LLM-as-a-judge evaluations, factuality metrics, and retrieval-grounding checks to identify when an AI model generates content not supported by its context or knowledge base.
Can I create custom evaluation metrics?
Yes. In addition to 100+ built-in metrics, you can define custom evaluations using any prompt-based LLM judge, rule-based classifier, or Python function—giving full flexibility for domain-specific quality checks.
Does Evidently support adversarial testing?
Yes. The platform includes tools to generate adversarial test cases—including jailbreak attempts, PII probing, and edge-case inputs—to stress-test AI systems against real-world threats before and after deployment.




