
U
About
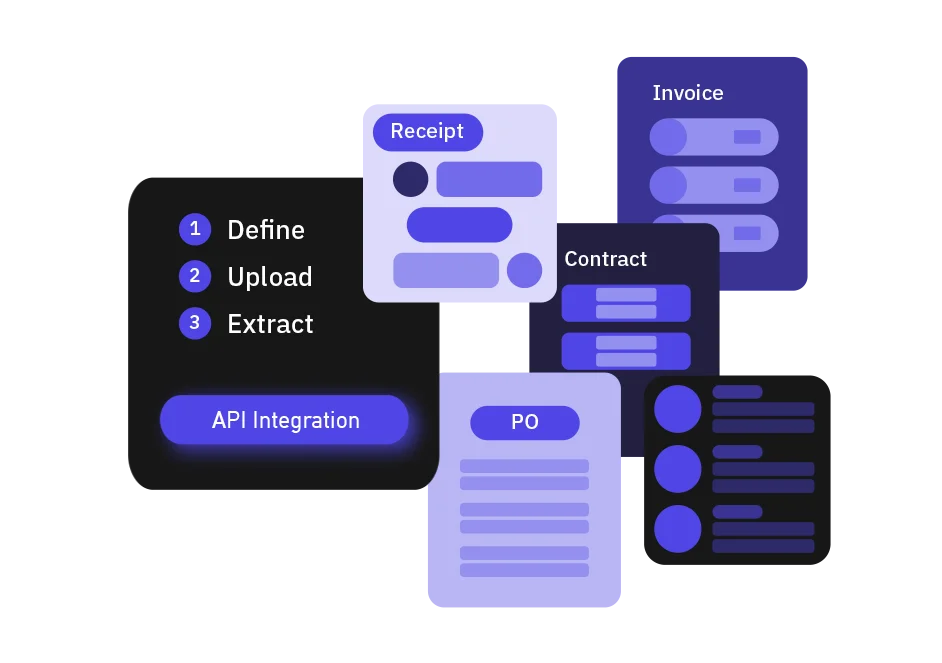
Extracta LABS is a no-training-required AI data extraction platform designed to automate how businesses process documents and images. Powered by a large language model (LLM) engine, it can intelligently identify and extract user-defined fields from virtually any document format, including PDFs, scanned images, digital documents, Word files, web pages, and plain text files. The platform ships with pre-built extraction templates for the most common business document types: invoices, resumes, contracts, receipts, bank statements, bills of lading, purchase orders, and emails. For non-standard or custom document layouts, users can define their own extraction criteria without any complicated setup or ML training pipelines. Key use cases span across departments — finance teams can automate invoice and receipt processing, HR departments can parse resumes and extract candidate qualifications, and legal teams can pull parties, dates, and contract terms with high accuracy. The platform also offers a full API, making it suitable for developers looking to integrate document extraction into their own applications or workflows. Exracta LABS is built for businesses of all sizes seeking to reduce manual data entry, minimize errors, and accelerate document-heavy workflows. Its simple interface and powerful AI backbone make it accessible to non-technical users while providing the flexibility and API depth that developers need.
Key Features
- No Training Required: Powered by an LLM engine, Extracta AI starts extracting data immediately — simply define the fields you need and upload your documents without any model training or complex setup.
- Multi-Format Document Support: Handles a wide range of file types including PDFs, scanned images, photos, digital documents, Word files, web pages, and plain text files.
- Pre-Built Document Templates: Comes with ready-to-use extraction templates for invoices, resumes, contracts, receipts, bank statements, bills of lading, purchase orders, and emails.
- Custom Field Extraction: Users can define custom extraction criteria for any unique or non-standard document layout, making the platform adaptable to virtually any use case.
- Full API Access: A comprehensive REST API lets developers integrate document extraction capabilities directly into their own applications, pipelines, and workflows.
Use Cases
- Finance teams automating invoice processing to eliminate manual data entry for dates, amounts, and vendor details.
- HR departments parsing large volumes of resumes to extract candidate skills, qualifications, and contact information for ATS integration.
- Legal teams extracting key contract terms, party names, and dates to streamline contract review and compliance workflows.
- Operations teams digitizing receipts and expense documents for accurate financial tracking and reconciliation.
- Developers building document processing pipelines by integrating Extracta's API into their own business applications or SaaS products.
Pros
- Zero Setup Friction: No model training, labeling, or technical configuration is required — users can begin extracting data from documents within minutes of signing up.
- Broad Document & Format Coverage: Supports an extensive range of document types and file formats out of the box, reducing the need for multiple tools across different document workflows.
- Flexible Customization: Custom extraction templates allow teams to adapt the tool to unique or proprietary document formats beyond the standard templates provided.
- Developer-Friendly API: A well-documented API makes it straightforward to embed extraction capabilities into existing systems or automate high-volume document processing pipelines.
Cons
- Pricing Transparency: Pricing details are not immediately visible without navigating to the pricing page, making it harder to evaluate cost at a glance.
- Complex Layout Accuracy: Highly unconventional or heavily stylized document layouts may yield less accurate extractions compared to standard structured formats.
- Dependency on Cloud Processing: As a cloud-based SaaS tool, it may not be suitable for organizations with strict data residency or on-premise processing requirements.
Frequently Asked Questions
What types of documents can Extracta AI handle?
Extracta AI supports invoices, resumes, contracts, receipts, bank statements, bills of lading, purchase orders, emails, and any custom document type. It processes PDFs, scanned images, photos, digital documents, Word files, and plain text files.
Do I need to train the AI model before using it?
No. Extracta LABS is powered by an LLM-driven engine that requires no training or labeling. Simply define the fields you want to extract and upload your documents — the AI handles the rest automatically.
Does Extracta AI offer an API for developers?
Yes. Extracta LABS provides a full API with dedicated documentation, allowing developers to integrate document extraction into their own applications, automate workflows, or build custom integrations.
Can I extract data from scanned documents or images?
Yes. The platform is designed to handle scanned documents and images, converting them into actionable structured data using AI-powered recognition — no pre-processing required.
Is there a free plan available?
Yes, Extracta LABS offers a free tier so users can try the platform without a credit card. Paid plans are available for higher volume usage and advanced features, accessible via the pricing page.



