
M
About
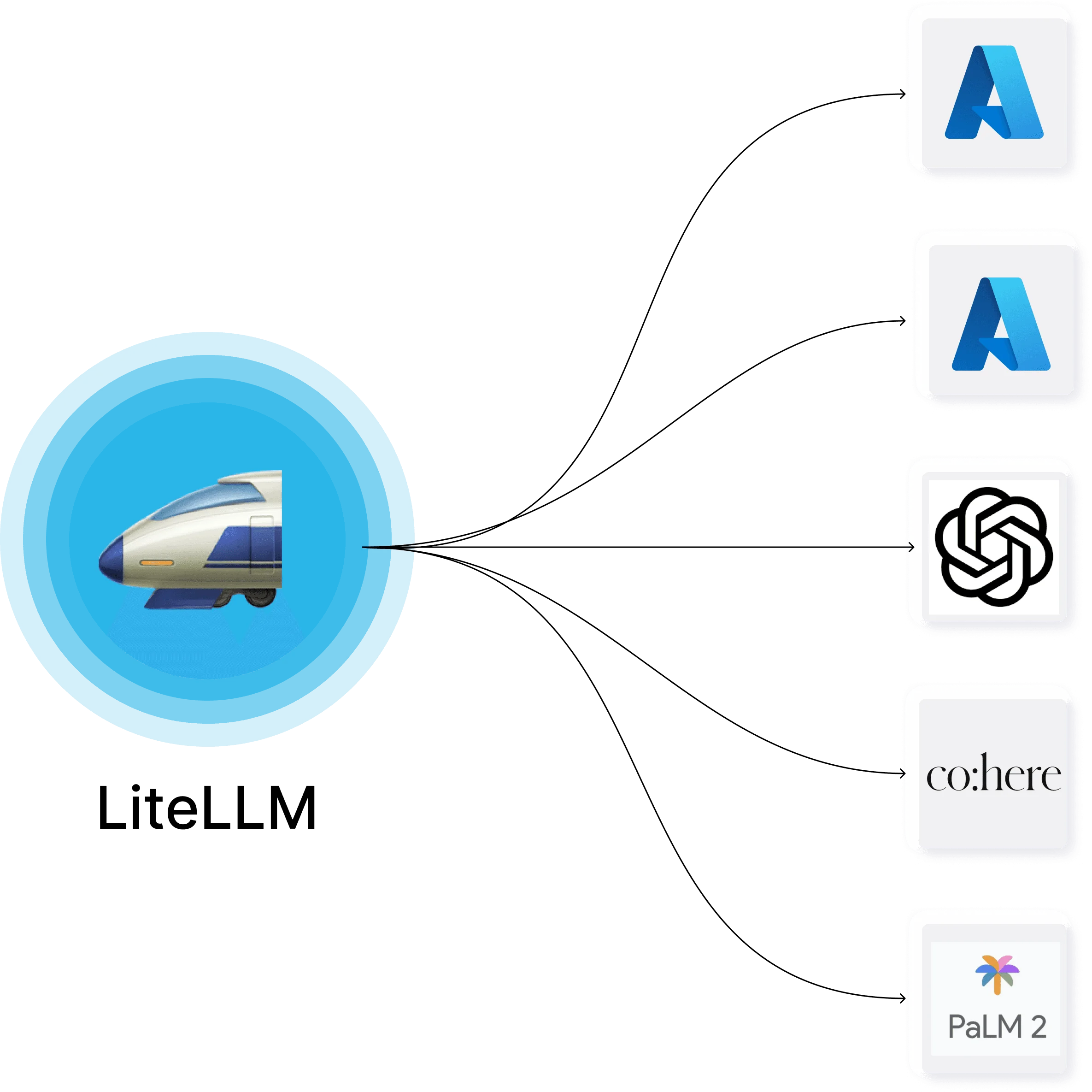
LiteLLM Proxy is a powerful, open-source AI gateway designed for platform and infrastructure teams that need to manage LLM access at scale. It exposes a unified OpenAI-compatible API so developers can call any of 100+ supported LLM providers—including OpenAI, Azure OpenAI, AWS Bedrock, Google Gemini, and Anthropic—without changing their code when switching models or providers. The platform's core value is simplifying multi-provider LLM management. Teams can assign virtual API keys tied to specific budgets, rate limits, and model permissions, making it easy to give developers scoped access without exposing raw provider credentials. Built-in spend tracking automatically attributes costs to keys, users, teams, or organizations across all providers, with support for tag-based tracking and logging to destinations like S3 or GCS. LiteLLM also supports LLM fallbacks—automatically routing requests to backup models when a primary provider is unavailable—along with load balancing across multiple deployments. Observability integrations with Langfuse, Arize Phoenix, Langsmith, and OpenTelemetry make it easy to monitor usage and debug issues. With over 240 million Docker pulls and 1 billion+ requests served, LiteLLM is battle-tested in production at companies like Netflix, Lemonade, and RocketMoney. It is available as a cloud-hosted service or fully self-hosted, with an enterprise tier offering SSO, JWT auth, audit logs, and custom SLAs.
Key Features
- Universal OpenAI-Compatible API: Access 100+ LLM providers through a single, standardized OpenAI-format endpoint—no SDK changes needed when switching models or providers.
- Spend Tracking & Budgets: Automatically track and attribute LLM costs to keys, users, teams, or organizations across all providers, with support for tag-based tracking and logging to S3/GCS.
- Virtual Keys & Rate Limiting: Issue scoped virtual API keys with per-key budgets, RPM/TPM limits, and model access controls so teams get the right access without exposing raw provider credentials.
- LLM Fallbacks & Load Balancing: Configure automatic fallback routing to backup models if a primary provider fails, and load balance requests across multiple deployments for reliability.
- Observability & Logging: Integrate natively with Langfuse, Arize Phoenix, Langsmith, and OpenTelemetry for full request tracing, cost dashboards, and LLM performance monitoring.
Use Cases
- Platform teams providing standardized, cost-tracked LLM access to hundreds of internal developers across multiple projects.
- Enterprises enforcing budget controls and rate limits on AI model usage per team or department.
- Organizations running multi-provider LLM strategies who need automatic failover and load balancing across OpenAI, Azure, and Bedrock.
- AI product teams standardizing their observability stack by routing all LLM calls through a single gateway with Langfuse or Langsmith integration.
- Startups that want to switch between LLM providers freely without rewriting application code each time.
Pros
- Massive Provider Coverage: Supports 100+ LLM providers out of the box, making it the most comprehensive gateway available for teams using multiple AI vendors.
- Open Source with Enterprise Option: The core product is free and self-hostable under an open-source license, with an optional enterprise tier for advanced auth, SSO, and SLAs.
- Battle-Tested at Scale: Used in production by Netflix, Lemonade, and RocketMoney with 240M+ Docker pulls and 1B+ requests served, demonstrating proven reliability.
- Drop-In OpenAI Compatibility: Any app built on the OpenAI SDK can immediately use LiteLLM Proxy with zero code changes, dramatically lowering the integration barrier.
Cons
- Self-Hosting Complexity: Running LiteLLM Proxy on-premise requires DevOps knowledge—Docker, configuration management, and monitoring all need to be set up and maintained by the team.
- Enterprise Features Behind Paywall: Advanced features like SSO, JWT auth, and audit logs are locked to the enterprise tier, which requires contacting sales for pricing.
- Documentation Depth Varies: With 100+ integrations, documentation quality and examples can vary significantly across less common providers or edge-case configurations.
Frequently Asked Questions
What is LiteLLM Proxy?
LiteLLM Proxy is an open-source LLM gateway that provides a single OpenAI-compatible API endpoint to route requests to 100+ LLM providers including OpenAI, Azure, AWS Bedrock, Google Gemini, and Anthropic. It handles authentication, load balancing, rate limiting, and spend tracking.
Is LiteLLM Proxy free to use?
Yes. The open-source version of LiteLLM Proxy is completely free and self-hostable. An enterprise tier with additional features like SSO, audit logs, and custom SLAs is available for teams with larger needs.
Can I use LiteLLM with my existing OpenAI-based code?
Yes. LiteLLM Proxy is fully compatible with the OpenAI API format, so any application already using the OpenAI SDK can point to LiteLLM Proxy without changing any code.
How does spend tracking work?
LiteLLM automatically calculates and attributes the cost of each LLM request to the associated virtual key, user, team, or organization. Spend data can be viewed in the dashboard or exported to S3, GCS, or other logging destinations.
Can I deploy LiteLLM Proxy in my own infrastructure?
Yes. LiteLLM Proxy can be self-hosted on-premises via Docker or deployed to any cloud environment. A managed cloud option is also available for teams that prefer not to manage the infrastructure themselves.




