
V
About
W&B Weave is a comprehensive observability and evaluation platform designed specifically for generative AI and LLM-powered applications. Built by Weights & Biases — the team behind the popular ML experiment tracking platform — Weave enables developers and ML teams to ship AI products with confidence by providing deep visibility into every layer of their AI stack. With just one line of code (`weave.init()`), teams can start tracing LLM calls, agent workflows, and custom functions. The platform automatically tracks quality, cost (token usage and estimated spend), latency, and safety metrics across any LLM or framework. Weave integrates natively with OpenAI, LangChain, LlamaIndex, and many others. Key capabilities include a rigorous evaluation suite with visual comparisons and automatic versioning of datasets, code, and scorers; an interactive Playground for iterating on prompts across multiple models; Leaderboards for comparing evaluation results across your organization; and Guardrails to block prompt injection attacks and harmful outputs. Production Monitors enable continuous quality improvement after deployment. Weave is ideal for ML engineers, AI developers, and enterprise teams building RAG pipelines, agentic systems, customer-facing LLM products, or any application where model quality and cost efficiency are critical. It bridges the gap between rapid experimentation and reliable production deployment for modern GenAI workflows.
Key Features
- LLM Tracing & Observability: Automatically trace every LLM call, agent step, and custom function with a single line of initialization code. Tracks quality, cost, latency, and safety in real time.
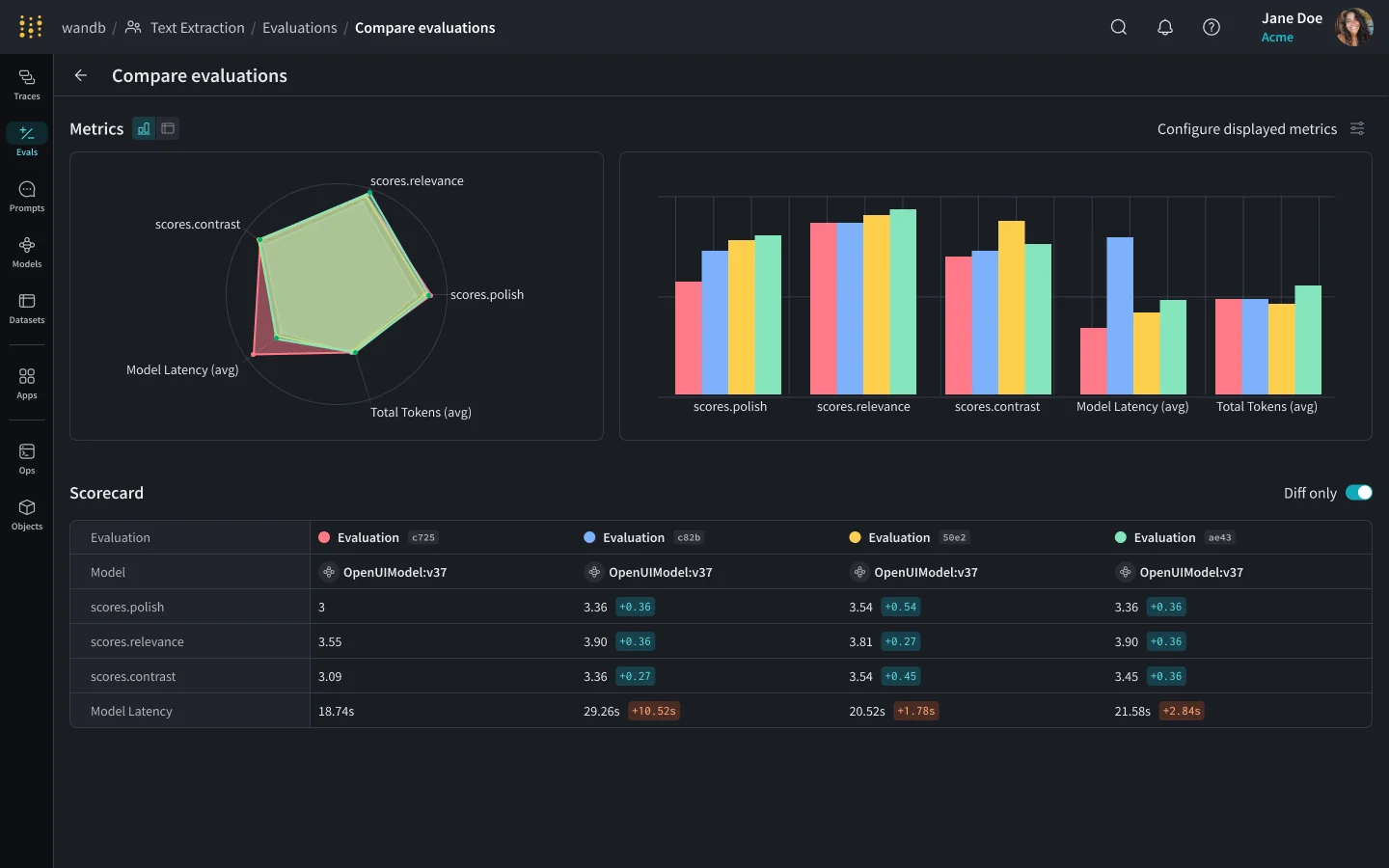
- Rigorous Evaluations: Run structured evaluations with visual comparisons, automatic versioning of datasets and scorers, and leaderboards to benchmark model performance across your team.
- Interactive Prompt Playground: Experiment with prompts across any supported LLM in a visual chat interface, enabling rapid iteration before deploying to production.
- Guardrails & Safety: Block prompt injection attacks and harmful outputs before they reach end users, with configurable guardrails built into the monitoring pipeline.
- Production Monitors: Continuously track deployed application quality and performance in production, enabling teams to detect regressions and iterate with confidence post-launch.
Use Cases
- Tracing and debugging LLM-powered chatbots and assistants to identify quality regressions or unexpected outputs.
- Running structured evaluations on RAG pipelines to compare retrieval strategies and response quality across model versions.
- Monitoring production GenAI applications for cost overruns, latency spikes, and safety policy violations.
- Iterating on system prompts and model selection in the Playground before rolling out changes to end users.
- Benchmarking multiple LLMs against custom evaluation datasets and sharing leaderboard results across engineering teams.
Pros
- Minimal Setup: Integrates with any LLM or framework with a single line of code, lowering the barrier to full observability.
- Comprehensive Metrics: Tracks quality, cost, latency, and safety together in one platform, eliminating the need for multiple monitoring tools.
- Strong Ecosystem Integrations: Works natively with OpenAI, LangChain, LlamaIndex, and other popular AI frameworks out of the box.
- Built for Teams: Leaderboards, shared evaluations, and organization-level insights make it easy for engineering teams to collaborate on model quality.
Cons
- Primarily Developer-Focused: Non-technical stakeholders may find the interface and SDK-centric workflow difficult to use without engineering support.
- Cost at Scale: High-volume production tracing and evaluation can incur significant costs on paid tiers, especially for large enterprise deployments.
- Learning Curve for Full Feature Set: While getting started is simple, unlocking advanced features like custom scorers, guardrails, and monitors requires deeper familiarity with the platform.
Frequently Asked Questions
What is W&B Weave?
W&B Weave is an evaluation and observability platform for generative AI applications, built by Weights & Biases. It helps developers trace LLM calls, run evaluations, monitor production quality, and iterate on prompts — all with minimal setup.
Does Weave work with any LLM or framework?
Yes. Weave is framework-agnostic and includes native integrations with popular tools like OpenAI, LangChain, LlamaIndex, and more. Any Python-based LLM application can be instrumented with a single line of code.
Is W&B Weave free to use?
Weave offers a free tier suitable for individuals and small teams. Paid plans are available for larger organizations that need higher usage limits, advanced features, and enterprise support.
What kinds of metrics does Weave track?
Weave tracks quality (accuracy, robustness, relevancy), cost (token usage and estimated spend), latency (response times and bottlenecks), and safety (harmful output detection and prompt attack blocking).
Can Weave be used for agentic AI systems?
Yes. Weave includes dedicated observability tools for agentic systems, allowing teams to trace multi-step agent workflows, monitor tool calls, and evaluate agent behavior in both development and production environments.


