
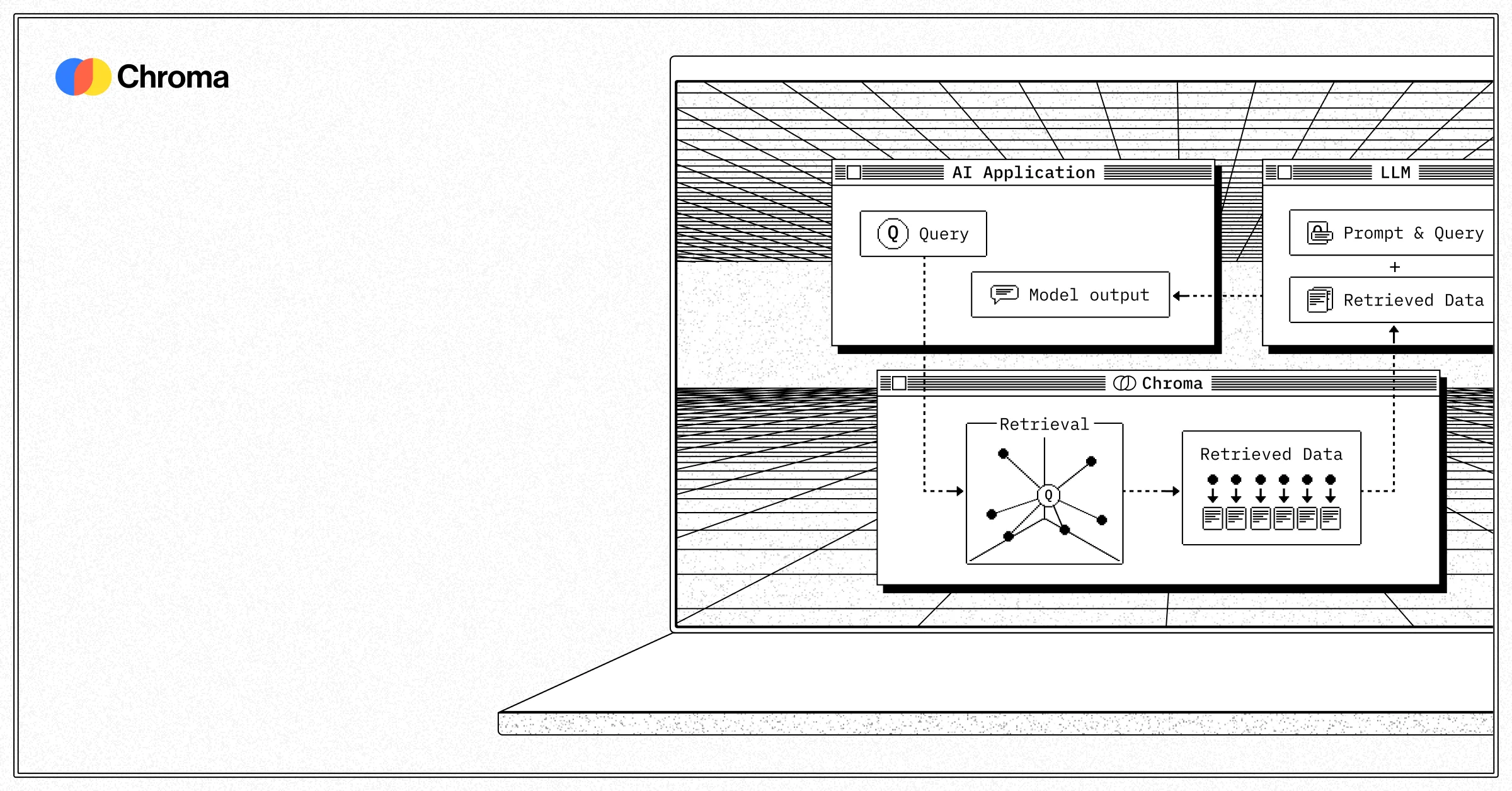

About
Chroma is a fast, scalable, and open-source search and retrieval database purpose-built for AI applications. Licensed under Apache 2.0, it enables developers to build AI apps that can intelligently know, learn, and search over large corpora of data. Chroma supports multiple search modalities including dense vector (semantic) search, sparse vector search (BM25/SPLADE), full-text and regex search, and metadata filtering with faceted queries. Built on object storage (S3/GCS), Chroma uses intelligent data tiering and caching to deliver low-latency queries at a fraction of the cost of legacy in-memory search systems—up to 10x cheaper than traditional alternatives. The cloud offering is fully serverless, requiring zero engineering ops, and auto-scales with data volume and traffic. Chroma is trusted by millions of developers with 5M+ monthly downloads and 24k GitHub stars. It ships official SDKs for Python, TypeScript, and Rust, making integration straightforward across stacks. Additional features include dataset forking for A/B testing and roll-outs, a CLI for local development, and SOC 2 Type II compliance for production workloads. For enterprises, Chroma offers BYOC (Bring Your Own Cloud) deployment inside your VPC, multi-cloud/multi-region replication, and point-in-time recovery. Chroma is the go-to infrastructure layer for RAG pipelines, AI agents, semantic search applications, and any LLM-powered product requiring fast and scalable knowledge retrieval.
Key Features
- Multi-Modal Search: Supports dense vector (semantic) search, sparse vector search (BM25/SPLADE), full-text and regex search, and metadata filtering in a single database.
- Serverless & Zero-Ops: Fully managed cloud offering that auto-scales with your data and traffic—no manual tuning, no infrastructure management required.
- Object Storage Architecture: Built on S3/GCS with intelligent query-aware data tiering and caching, making it up to 10x cheaper than legacy in-memory search systems.
- Multi-Language SDKs: Official SDKs for Python, TypeScript, and Rust enable quick integration into any modern AI application stack.
- Enterprise BYOC Deployment: Deploy Chroma inside your own VPC with multi-cloud/multi-region replication, point-in-time recovery, and SOC 2 Type II compliance.
Use Cases
- Building RAG (Retrieval-Augmented Generation) pipelines that give LLMs access to private or up-to-date knowledge bases.
- Powering semantic search features in AI applications, allowing users to query by meaning rather than exact keywords.
- Storing and retrieving document embeddings for AI agents that need long-term memory or context recall.
- Running A/B tests and dataset versioning on embedding collections using Chroma's forking feature.
- Replacing or augmenting traditional keyword search engines with hybrid vector + full-text search for enterprise applications.
Pros
- Open Source with Apache 2.0: Fully open-source under Apache 2.0, allowing free use, modification, and self-hosting with no licensing restrictions.
- Extremely Cost-Efficient: Object storage-based architecture is up to 10x cheaper than traditional in-memory vector databases, dramatically reducing infrastructure costs at scale.
- Broad Search Capabilities: Combines semantic, lexical, full-text, and metadata search in one system, eliminating the need for multiple specialized search tools.
- Massive Developer Adoption: With 5M+ monthly downloads and 24k GitHub stars, Chroma has a large, active community and well-maintained ecosystem.
Cons
- Cold Query Latency: Cold-start queries (data not yet cached) can have p50 latency around 650ms, which may be noticeable for latency-sensitive real-time applications.
- Enterprise Features Are Paid: Advanced capabilities like BYOC, multi-region replication, and point-in-time recovery require an enterprise contract.
- Per-Collection Concurrency Limits: Default cloud tier has concurrency limits per collection (10 concurrent reads, 200+ QPS), which may require dedicated cluster upgrades for very high-traffic workloads.
Frequently Asked Questions
What is Chroma used for?
Chroma is primarily used as the retrieval layer in RAG (Retrieval-Augmented Generation) pipelines, AI agents, semantic search engines, and any LLM-powered application that needs to store and query embeddings or documents at scale.
Is Chroma free to use?
Yes. Chroma is open-source under the Apache 2.0 license and can be self-hosted for free. A managed cloud product is also available with a free tier, while enterprise features (BYOC, replication, etc.) are available under a paid plan.
How does Chroma differ from other vector databases?
Chroma is built on object storage (S3/GCS) rather than in-memory architectures, making it significantly cheaper at scale. It also combines vector, sparse vector, full-text, regex, and metadata search in one system, whereas many competitors focus only on vector similarity.
What programming languages does Chroma support?
Chroma provides official SDKs for Python, TypeScript/JavaScript, and Rust. It can be run locally or accessed via the managed cloud API.
Can Chroma be deployed in my own cloud infrastructure?
Yes. Through Chroma's enterprise offering, you can deploy Chroma's data plane inside your own VPC (BYOC) across AWS, GCP, or Azure, while the control plane (monitoring, backups, ops) is managed by Chroma.








